

ЛСЛчТэЗжөДҙҰАн¶ФПуКЗ»ҘБӘНшНшТіЈ¬ИХЗ°НшТіКэБҝТФ°ЩТЪјЖЈ¬ЛщТФЛСЛчТэЗжКЧПИГжБЩөДОКМвҫНКЗЈәИзәОДЬ№»ЙијЖіцёЯР§өДПВФШПөНіЈ¬ТФҪ«ИзҙЛәЈБҝөДНшТіКэҫЭҙ«ЛНөҪұҫөШЈ¬ФЪұҫөШРОіЙ»ҘБӘНшНшТіөДҫөПсұё·ЭЎЈ
НшВзЕАіжјҙЖрҙЛЧчУГЈ¬ЛьКЗЛСЛчТэЗжПөНіЦРәЬ№ШјьТІёщ»щҙЎөД№№јюЎЈХвАпЦчТӘҪйЙЬУлНшВзЕАіжПа№ШөДјјКхЈ¬ҫЎ№ЬЕАіжјјКхҫӯ№эјёК®ДкөД·ўХ№Ј¬ҙУХыМеҝтјЬЙПТСПа¶ФіЙКмЈ¬ө«ЛжЧЕБӘНшөДІ»¶П·ўХ№Ј¬ТІГжБЩЧЕТ»Р©УРМфХҪРФөДРВОКМвЎЈ
ПВНјЛщКҫКЗТ»ёцНЁУГөДЕАіжҝтјЬБчіМЎЈКЧПИҙУ»ҘБӘНшТіГжЦРҫ«РДСЎФсТ»Іҝ·ЦНшТіЈ¬ТФХвР©НшТіөДБҙҪУөШЦ·ЧчОӘЦЦЧУURLЈ¬Ҫ«ХвР©ЦЦЧУURL·ЕИлҙэЧҘИЎURL¶УБРЦРЈ¬ЕАіжҙУҙэЧҘИЎURL¶УБРТАҙО¶БИЎЈ¬ІўҪ«URLНЁ№эDNSҪвОцЈ¬°СБҙҪУөШЦ·ЧӘ»»ОӘНшХҫ·юОсЖч¶ФУҰөДIPөШЦ·ЎЈ
И»әуҪ«ЖдәННшТіПа¶ФВ·ҫ¶ГыіЖҪ»ёшНшТіПВФШЖчЈ¬НшТіПВФШЖчёәФрТіГжДЪИЭөДПВФШЎЈ¶ФУЪПВФШөҪұҫөШөДНшТіЈ¬Т»·ҪГжҪ«ЖдҙжҙўөҪТіГжҝвЦРЈ¬өИҙэҪЁБўЛчТэөИәуРшҙҰАн;БнТ»·ҪГжҪ«ПВФШНшТіөДURL·ЕИлТСЧҘИЎURL¶УБРЦРЈ¬Хвёц¶УБРјЗФШБЛЕАіжПөНіТСҫӯПВФШ№эөДНшТіURLЈ¬ТФұЬГвНшТіөДЦШёҙЧҘИЎЎЈ¶ФУЪёХПВФШөДНшТіЈ¬ҙУЦРійИЎіцЛщ°ьә¬өДЛщУРБҙҪУРЕПўЈ¬ІўФЪТСЧҘИЎURL¶УБРЦРјмІйЈ¬Из№ы·ўПЦБҙҪУ»№Г»УРұ»ЧҘИЎ№эЈ¬ФтҪ«ХвёцURL·ЕИлҙэЧҘИЎURL¶УБРД©ОІЈ¬ФЪЦ®әуөДЧҘИЎөч¶ИЦР»бПВФШХвёцURL¶ФУҰөДНшТіЎЈИзҙЛХв°гЈ¬РОіЙСӯ»·Ј¬ЦұөҪҙэЧҘИЎURL¶УБРОӘЙуЈ¬ХвҙъұнЧЕЕАіжПөНіТСҪ«ДЬ№»ЧҘИЎөДНшТіҫЎКэЧҘНкЈ¬ҙЛКұНкіЙБЛТ»ВЦНкХыөДЧҘИЎ№эіМЎЈ
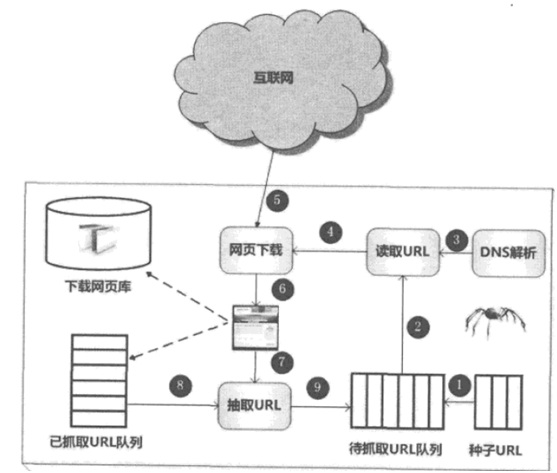
¶ФУЪЕАіжАҙЛөЈ¬НщНщ»№РиТӘҪшРРНшТіИҘЦШј°НшТі·ҙЧчұЧЎЈ
ЙПКцКЗТ»ёцНЁУГЕАіжөДХыМеБчіМЈ¬Из№ыҙУёьјУәк№ЫөДҪЗ¶ИҝјВЗЈ¬ҙҰУЪ¶ҜМ¬ЧҘИЎ№эіМЦРөДЕАіжәН»ҘБӘНшЛщУРНшТіЦ®јдөД№ШПөЈ¬ҝЙТФҙуЦВПсИзНј2-2ЛщЙнДЗСщЈ¬Ҫ«»ҘБӘНшТіГж»®·ЦОӘ5ёцІҝ·ЦЈә
1.ТСПВФШНшТіјҜәПЈәЕАіжТСҫӯҙУ»ҘБӘНшПВФШөҪұҫөШҪшРРЛчТэөДНшТіјҜәПЎЈ
2.ТС№эЖЪНшТіјҜәПЈәУЙУЪНшТіКэЧоҫЮҙуЈ¬ЕАіжНкХыЧҘИЎТ»ВЦРиТӘҪПіӨКұјдЈ¬ФЪЧҘИЎ№эіМЦРЈ¬әЬ¶аТСҫӯПВФШөДНшТіҝЙДЬ№эЖЪЎЈЦ®ЛщТФИзҙЛЈ¬КЗТтОӘ»ҘБӘНшНшТіҙҰУЪІ»¶ПөД¶ҜМ¬ұд»Ҝ№эіМЦРЈ¬ЛщТФТЧІъЙъұҫөШНшТіДЪИЭәНХжКө»ҘБӘНшНшТіІ»Т»ЦВөДЗйҝцЎЈ
3.ҙэПВФШНшТіјҜәПЈәјҙҙҰУЪЙПНјЦРҙэЧҘИЎURL¶УБРЦРөДНшТіЈ¬ХвР©НшТіјҙҪ«ұ»ЕАіжПВФШЎЈ
4.ҝЙЦӘНшТіјҜәПЈәХвР©НшТі»№Г»УРұ»ЕАіжПВФШЈ¬ТІГ»УРіцПЦФЪҙэЧҘИЎURL¶УБРЦРЈ¬І»№эНЁ№эТСҫӯЧҘИЎөДНшТі»тХЯФЪҙэЧҘИЎURL¶УБРЦРөДНшТіЈ¬ЧЬЧгДЬ№»НЁ№эБҙҪУ№ШПө·ўПЦЛьГЗЈ¬ЙФНнКұәт»бұ»ЕАіжЧҘИЎІўЛчТэЎЈ
5.І»ҝЙЦӘНшТіјҜәПЈәУРР©НшТі¶ФУЪЕАіжАҙЛөКЗОЮ·ЁЧҘИЎөҪөДЈ¬ХвІҝ·ЦНшТі№№іЙБЛІ»ҝЙЦӘНшТіјҜәПЎЈКВКөЙПЈ¬ХвІҝ·ЦНшТіЛщХјөДұИАэәЬёЯЎЈ
ёщҫЭІ»Н¬өДУҰУГЈ¬ЕАіжПөНіФЪРн¶а·ҪГжҙжФЪІоТмЈ¬ҙуМе¶шСФЈ¬ҝЙТФҪ«ЕАіж»®·ЦОӘИзПВИэЦЦАаРН:
1. ЕъБҝРНЕАіжЈЁBatch CrawlerЈ©ЈәЕъБҝРНЕАіжУРұИҪПГчИ·өДЧҘИЎ·¶О§әНДҝұкЈ¬өұЕАіжҙпөҪХвёцЙи¶ЁөДДҝұкәуЈ¬јҙНЈЦ№ЧҘИЎ№эіМЎЈЦБУЪҫЯМеДҝұкҝЙДЬёчТмЈ¬ТІРнКЗЙи¶ЁЧҘИЎТ»¶ЁКэБҝөДНшТіјҙҝЙЈ¬ТІРнКЗЙи¶ЁЧҘИЎПыәДөДКұјдөИЎЈ
2.ФцБҝРНЕАіжЈЁIncremental CrawlerЈ©ЈәФцБҝРНЕАіжУлЕъБҝРНЕАіжІ»Н¬Ј¬»бұЈіЦіЦРшІ»¶ПөДЧҘИЎЈ¬¶ФУЪЧҘИЎөҪөДНшТіЈ¬ТӘ¶ЁЖЪёьРВЈ¬ТтОӘ»ҘБӘНшөДНшТіҙҰУЪІ»¶Пұд»ҜЦРЈ¬РВФцНшТіЎўНшТіұ»Йҫіэ»тХЯНшТіДЪИЭёьёД¶јәЬіЈјыЈ¬¶шФцБҝРНЕАіжРиТӘј°Кұ·ҙУіХвЦЦұд»ҜЈ¬ЛщТФҙҰУЪіЦРшІ»¶ПөДЧҘИЎ№эіМЦРЈ¬І»КЗФЪЧҘИЎРВНшТіЈ¬ҫНКЗФЪёьРВТСУРНшТіЎЈНЁУГөДЙМТөЛСЛчТэЗжЕАіж»щұҫ¶јКфҙЛАаЎЈ
3.ҙ№ЦұРНЕАіж(Focused CrawterЈ©Јәҙ№ЦұРНЕАіж№ШЧўМШ¶ЁЦчМвДЪИЭ»тХЯКфУЪМШ¶ЁРРТөөДНшТіЈ¬ұИИз¶ФУЪҪЎҝөНшХҫАҙЛөЈ¬Ц»РиТӘҙУ»ҘБӘНшТі¶шАпХТөҪУлҪЎҝөПа№ШөДТіГжДЪИЭјҙҝЙЈ¬ЖдЛыРРТөөДДЪИЭІ»ФЪҝјВЗ·¶О§ЎЈҙ№ЦұРНЕАіжТ»ёцЧоҙуөДМШөгәНДСөгҫНКЗЈәИзәОК¶ұрНшТіДЪИЭКЗ·сКфУЪЦё¶ЁРРТө»тХЯЦчМвЎЈҙУҪЪКЎПөНіЧКФҙөДҪЗ¶ИАҙЛөЈ¬І»М«ҝЙДЬ°СЛщУР»ҘБӘНшТіГжПВФШПВАҙЦ®әуФЩИҘЙёСЎЈ¬ХвСщАЛ·СЧКФҙҫНМ«№э·ЦБЛЈ¬НщНщРиТӘЕАіжФЪЧҘИЎҪЧ¶ОҫНДЬ№»¶ҜМ¬К¶ұрДіёцНшЦ·КЗ·сУлЦчМвПа№ШЈ¬ІўҫЎБҝІ»ИҘЧҘ¶ХОЮ№ШТіГжЈ¬ТФҙпөҪҪЪКЎЧКФҙөДДҝөДЎЈҙ№ЦұЛСЛчНшХҫ»тХЯҙ№ЦұРРТөНшХҫНщНщРиТӘҙЛЦЦАаРНөДЕАіжЎЈ